Limited Time Offer!
For Less Than the Cost of a Starbucks Coffee, Access All DevOpsSchool Videos on YouTube Unlimitedly.
Master DevOps, SRE, DevSecOps Skills!

In a high-stakes production environment, maintaining optimal server performance is crucial for ensuring applications run smoothly and meet user demands. Even minor performance issues can escalate, leading to slow response times, system crashes, or downtimes that directly impact productivity, revenue, and user satisfaction. Linux servers, known for their reliability and flexibility, are often the backbone of these critical applications, making it essential for system administrators, DevOps engineers, and developers to be well-versed in troubleshooting techniques that pinpoint performance bottlenecks.
Performance troubleshooting on Linux involves monitoring key system metrics—CPU, memory, disk I/O, and network bandwidth—to understand server health and efficiency. By interpreting these metrics effectively, administrators can diagnose issues early, address resource limitations, and make informed decisions about scaling, optimizing code, or enhancing infrastructure. Each component plays an interconnected role; for instance, high memory usage might indicate a need for memory optimization in the application, or elevated disk I/O could signal intensive database queries or improper logging levels.
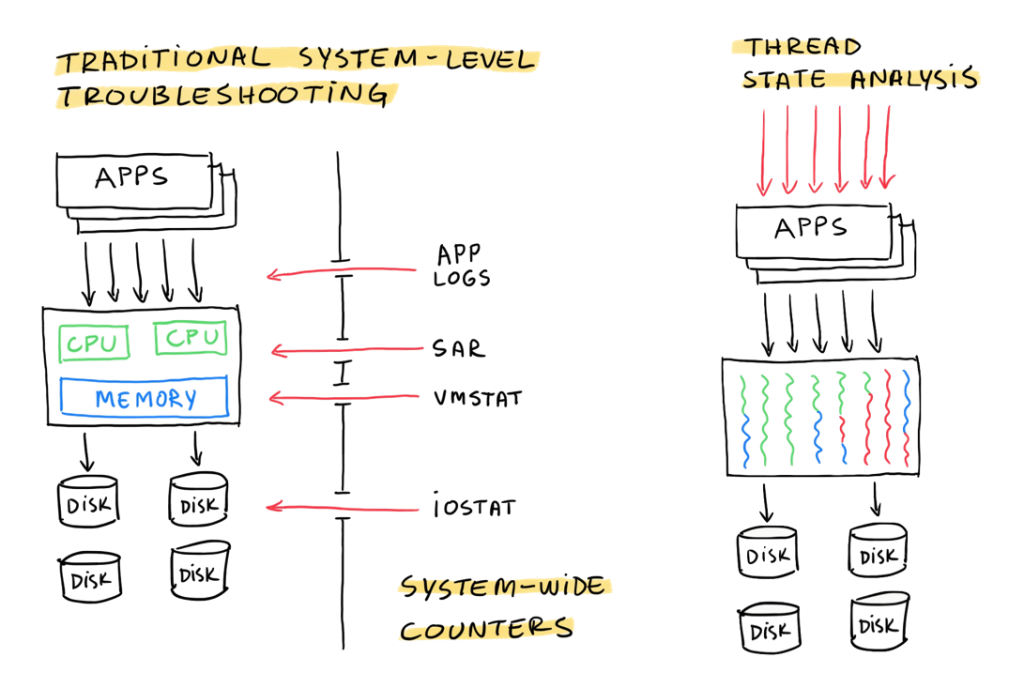
Fundamental Linux commands for performance Troubleshooting
This guide is a comprehensive look at the fundamental Linux commands for performance troubleshooting. It offers a practical, deep dive into each tool, explaining how to interpret the output for real-world scenarios and recognize when particular metrics indicate potential problems. With these tools, you will be able to monitor system health in real-time, investigate root causes behind unexpected slowdowns, and address issues effectively before they impact end users. Whether you’re dealing with spikes in traffic, resource-intensive applications, or routine maintenance, these commands will empower you to keep your production servers running smoothly and efficiently, ensuring reliability and resilience in a dynamic environment.
This collection of Linux commands is designed for daily use, allowing you to gain insight into your production server’s performance with ease, speed, and accuracy. Mastering these commands will help you build a proactive approach to server maintenance, positioning you to catch issues before they affect performance and improving your overall capacity to manage critical Linux-based systems effectively.
1. Check System Load and Uptime
- Command:
uptime - Usage: Provides system uptime, load averages for the last 1, 5, and 15 minutes.
- Interpretation: Load average values near the number of CPU cores are manageable. Higher values indicate load issues.
uptime2. Monitor CPU Usage
- Command:
top - Usage: Real-time display of CPU, memory, and process information. Useful for identifying high CPU usage processes.
- Shortcut Tips in
top:Pto sort by CPU usage.Mto sort by memory.qto quit.- Command –
top - Command:
mpstat - Usage: Shows CPU usage across cores.
- Interpretation: Idle time close to 0% and high system/user times indicate heavy load.
- mpstat -P ALL
3. Memory Usage and Swapping
- Command:
free -h - Usage: Shows free and used memory.
- Interpretation: If swap usage is high, consider optimizing memory usage.
- Command:
vmstat - Usage: Detailed breakdown of memory, CPU, and I/O activity.
- Interpretation: Look for high swap-in/swap-out, which can slow down performance.
vmstat 1 5 # Every second, 5 times
4. Disk I/O Performance
- Command:
iostat - Usage: Disk I/O statistics.
- Interpretation: High values in the
awaitandsvctmcolumns suggest I/O delays. - Command: iotop
- Usage: Real-time I/O monitoring for each process.
- Interpretation: Identify processes causing heavy I/O.
5. Disk Usage
- Command:
df -h - Usage: Displays disk space usage.
- Interpretation: Look for partitions with over 90% utilization.
- Command:
du -sh /path/to/directory - Usage: Disk usage for specific directories.
- Interpretation: Helps pinpoint directories using significant storage.
du -sh /var/log # Disk usage for logs
6. Network Performance
- Command:
ifconfigorip a - Usage: Checks network interface details and IP addresses.
- Command:
ping - Usage: Checks connectivity to another server or domain.
- Interpretation: High latency or packet loss can indicate network issues.
- Command:
netstat -tulnp - Usage: Lists listening ports and connections.
- Interpretation: Useful for identifying network bottlenecks.
- Command:
ss -s - Usage: Summary of socket statistics.
- Interpretation: Useful for understanding network connections.
7. Check Logs for Errors
- Command:
tail -f /var/log/syslog - Usage: View system logs in real-time.
- Command:
journalctl -xe - Usage: View recent and critical system logs.
- Interpretation: Useful for systemd-based logs.
8. Process Management
- Command:
ps aux --sort=-%cpu | head - Usage: Displays top processes by CPU usage.
- Command:
kill -9 PID - Usage: Terminate a misbehaving process.
9. Advanced Performance Analysis
- Command:
strace -p PID - Usage: Traces system calls for a specific process.
- Interpretation: Helps debug application issues causing high CPU or memory usage.
- Command:
dstat - Usage: Combines CPU, disk, network, and memory usage in one view.
- Interpretation: Ideal for real-time troubleshooting.
10. Resource Limits
- Command:
ulimit -a - Usage: Displays user limits on resources like file handles, memory, and more.
- Interpretation: Adjust limits if they are too restrictive for the server’s load.
Why Linux Performance Troubleshooting is Essential for Production Servers
In today’s digital landscape, where user expectations for speed and reliability are constantly increasing, production servers serve as the backbone of countless business operations, applications, and services. Organizations rely heavily on their infrastructure to operate without interruptions, meaning that even brief performance issues can have significant negative consequences. From e-commerce platforms to enterprise software and web services, slow or unresponsive servers lead to lost revenue, diminished user satisfaction, and even damage to brand reputation.
Linux servers are commonly chosen for production environments because of their stability, flexibility, and open-source nature, which allows organizations to optimize them for various workloads. However, even with these strengths, no server is immune to performance issues. Routine spikes in traffic, resource-intensive applications, or unexpected hardware constraints can strain the server and degrade its performance. Without effective troubleshooting skills, diagnosing the exact cause of these slowdowns or outages can become a time-consuming process, delaying the resolution and potentially exacerbating the impact on users and stakeholders.
Performance troubleshooting on Linux is essential because it enables administrators to:
- Identify Bottlenecks Quickly: The ability to rapidly pinpoint issues such as high CPU usage, memory leaks, or network congestion is invaluable. This allows teams to resolve issues before they affect end users and helps maintain consistent performance.
- Optimize Resources Proactively: By understanding how resources are consumed, teams can make data-driven adjustments to memory allocation, disk usage, and application configurations to optimize server performance.
- Ensure Reliability and Uptime: System reliability is often a priority in production environments. Regular monitoring and troubleshooting can prevent minor issues from escalating into severe outages, preserving uptime and stability.
- Support Scalability: As businesses grow and traffic increases, the server’s workload may evolve. Effective troubleshooting reveals when it’s time to scale resources or make architectural adjustments to support growth without performance degradation.
In essence, mastering Linux performance troubleshooting helps administrators and DevOps engineers build a robust foundation for server health, ensuring that production environments remain responsive, reliable, and scalable in the face of increasing demand. This approach not only saves time during critical incidents but also contributes to a culture of proactive monitoring and maintenance, where issues are resolved before they impact users, ultimately supporting a better experience and higher operational efficiency.